
Let your team vibe code -
without losing control
AI coding agents are powerful. But they execute Skills with no security review, and run commands with no policy enforcement. Enkrypt AI gives you both layers: scan before execution, govern during it.
Works with

Security gaps at every stage of execution
Scanning catches threats before they run. Guardrails catch behavior that shouldn't run - even from Skills that look clean. You need both.
.cursor/skills/ or .claude/skills/ directory, they're installing behavior that controls what their AI agent does. A malicious Skill can silently steal credentials before anyone notices.Real attacks - demonstrated by Enkrypt AI
Each attack requires a different layer to catch it. Scanning alone or runtime governance alone leaves you exposed.
Scan the supply chain. Govern the runtime.
Scanning catches threats before they execute. Guardrails enforce policy while agents are running. You need both.
What Skill Sentinel and Guardrails catch
Mapped to OWASP Top 10 for LLM Applications and OWASP Top 10 for Agentic Applications.
From clone to governed in four steps
Skill Sentinel scans before execution. Guardrails enforce during execution. Both produce evidence.
Run Skill Sentinel on .cursor/skills/ and .claude/skills/ - in CI or locally
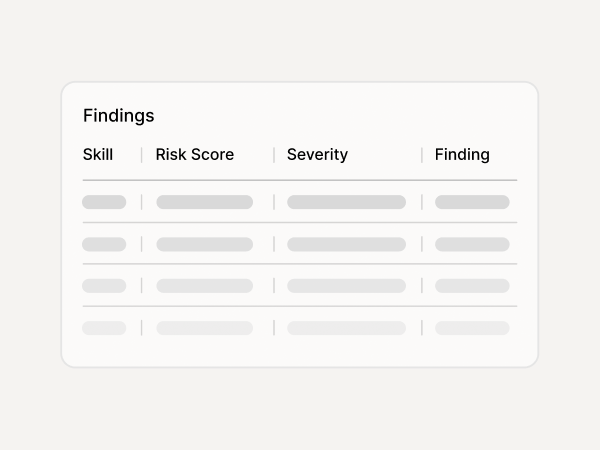
Triage findings, block malicious Skills, approve safe ones into your allowlist

Integrate runtime enforcement - command allowlists, data policies, approval gates
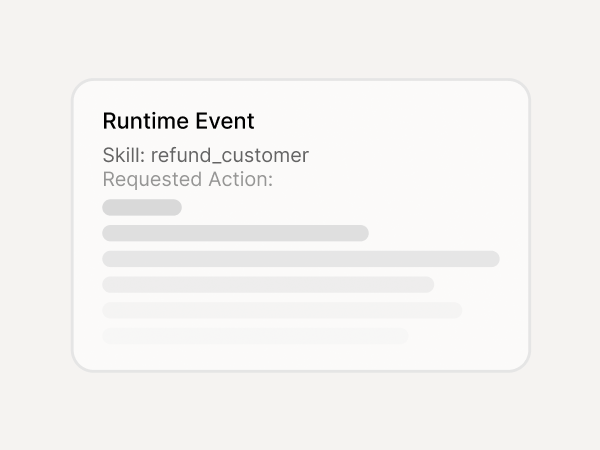
Every enforcement decision logged with policy_id - export to SIEM or audit packet
Running in minutes, not sprints
Skill Sentinel is open source and installs with pip. Guardrails integrate via hooks or proxy.
Skill Sentinel - scan your Skills
# Install
pip install skill-sentinel
# Scan a single Skill
skill-sentinel scan --skill ./my-skill
# Scan all Cursor skills in parallel
skill-sentinel scan cursor --parallel
# Auto-discover and scan everything
skill-sentinel scan
# CI/CD integration
skill-sentinel scan --dir .cursor/skills/
skill-sentinel scan --dir .claude/skills/Guardrails - enforce at runtime
# Hook into your coding agent
# via API wrapper, proxy, or SDK
# Define a policy pack
policy:
block_commands:
- curl, wget, nc, ssh
- pip install, npm install
block_file_access:
- ~/.ssh/*, ~/.aws/*
- .env, *.pem, *.key
require_approval:
- deploy, publish, push
- rm -rf, chmod, chown
# Every decision → policy_id + traceWorks with the coding agents your team already uses
Skill Sentinel scans Skills from any provider. Guardrails hook into any agent's execution path.

Frequently Asked Questions
skill-sentinel scan --dir .cursor/skills/ as a CI step. It produces JSON reports with severity levels, evidence, and remediation recommendations. Gate your pipeline on the results - block merges that introduce malicious or suspicious Skills.- (1) Install Skill Sentinel and scan all Skills in your repos today - it takes five minutes.
- (2) Disable auto-execution in your coding agents and require explicit approval for commands.
- (3) Add CODEOWNERS rules to require security review for changes to .cursor/ and .claude/ directories. These three steps cover the most critical gaps while you evaluate the full Guardrails integration.
